Learning Logic Programs from Dynamic Systems
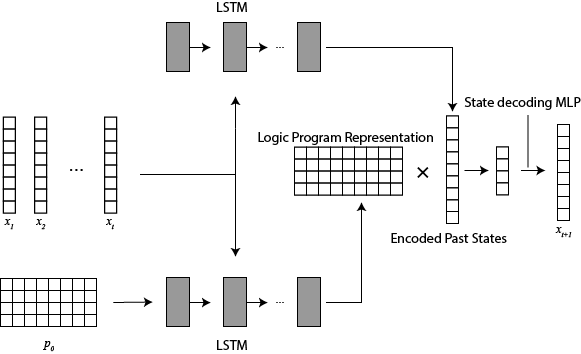

My main research focus has been on a neuro-symbolic method to learn transition rules from time series data. Using a singular neural network to learn to classify different time series that originate from different dynamic systems, we have shown that it was possible to predict the next state from just the historical data (Phua, et al. 27th International Conference on Inductive Logic Programming, 2017). By inputting the time series into an LSTM (Long-Short Term Memory) and using the corresponding logic program as the hidden states, the LSTM was able to learn representations of the logic program and used the representation to predict the next state. Next, we have also shown that neural network can identify different time series that come from the same dynamic system, and we also revised our method to take into account background knowledge (Phua, et al. IfCoLog Journal of Applied Logics, 2019). By training the LSTM to identify different time series from the same system, we were able to improve the accuracy of our method.
Using the above results, and leveraging the strength of neural networks for pattern recognition, we proposed a method that learns logical rules from state transition data (Phua, et al. 29th International Conference on Inductive Logic Programming, 2019). By classifying the rules that are inherent within the state transitions, it becomes possible to output a logic program that represents the dynamic system. To train the neural network to classify all possible rules, we set some constraint on the learned rules. By not touching the architecture of the neural network itself, but levaraging the neural network for classification of logical rules, we were able to prove that the resulting method is robust again noise. This work was recognized by the community, and we received the Best Student Paper award. Next, by utilizing some of the invariant properties that are inherent in logic systems, we managed to surpress the combinatorial explosion problem that comes from trying to classify all possible rules (Phua, et al. 1st International Joint Conference on Learning & Reasoning, 2021). In particular, we look at the invariant in the order of the state transition input, and we proposed a neural network architecture that takes the invariance into consideration. In addition to that, by considering multiple logical rules in one inference, we were able to reduce the memory requirements of the neural network. Therefore, we were able to apply our method to larger dynamic systems, and it brings us a step closer to real world applications.
We have also extended our method to delayed dynamic systems, and have also shown robustness against missing data. We were also able to extend our method to asynchronous semantics, instead of the synchronous semantics that all of our previous method considered.
Class-Incremental Learning using Generative Models

Statistical machine learning methods like neural networks are known to suffer from catastrophic forgetting. Given a model that has already been trained on a task, if we train the model on a new task, all knowledge regarding the previous task is lost. The field of studying this phenomenon and attempts for mitigating this, is called incremental learning. One part of it considers the task of classification, where at each training step, only a limited number of classes are available. Many different methods have been proposed with various degrees of success, and one method we consider is the method utilizing distillation and replay memory. Knowledge distillation is a method to train a model to retain knowledge from another model. Whereas replay memory is having a fixed amount of memory for previous classes. Previous methods have used instances from the training dataset to retain them as memory. However, as only a limited amount of memory is available, we can only retain a fixed amount of instances. This limits the performance of such method. In this work, we proposed a method that utilizes widely available generative models and replace them as the replay memory. We devised a method to prompt the generative model to obtain relevant images. By doing this, we were able to improve existing methods by 1~3%. We also found that there is a sweet spot between the final accuracy and the amount of images that we obtain from the generative models.
Results of this work has been published in the workshop paper (Jodelet, et al. 1st Workshop on Visual Continual Learning, 2023) and has been chosen for the best paper award.
Consistent Identification of Gene Sets from Cell Sequencing Data
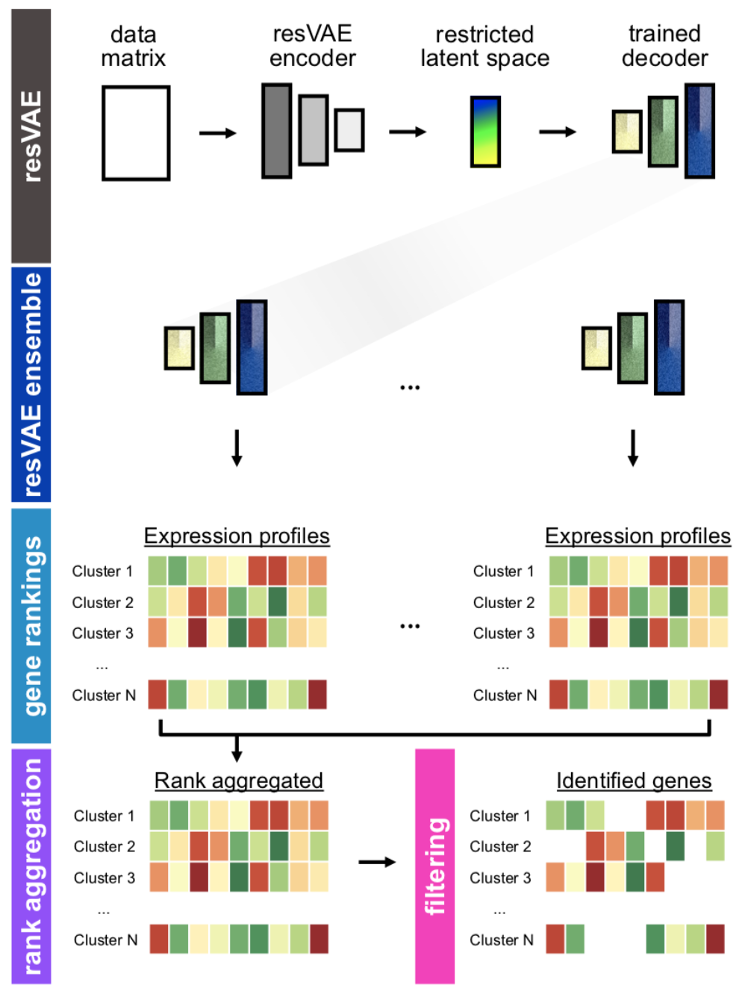
In collaboration with Berlin Institute of Health, we proposed a method to identify important gene sets based on the cell types from single cell sequencing data. Biologists face time pressure in analyzing cell sequencing data. Identifying gene sets quickly can help the efficiency of the development of important drugs. Previous methods only focused on the possibility of extracting gene sets, but due to randomness in statistical machine learning methods, each run potentially produces different gene sets, complicating the analysis for biologists. By utilizing an ensemble of resVAEs, we were able to stabilize the results of identified gene-sets. Further, we also show that the choice of activation function has huge implications on the stability of the results, thus we chose an activation function that provides even greater stability.
Results of this work were published in the journal paper (Ten, et al. Frontiers in Cell and Developmental Biology 11, 2023).
Have questions or want to know more about my research work? You can always contact me by email.