What didn't make it into the paper: the NRI research diary
Published on May 11, 2026
Six months of fixing what wasn't broken, and finally hearing what the model was telling us.
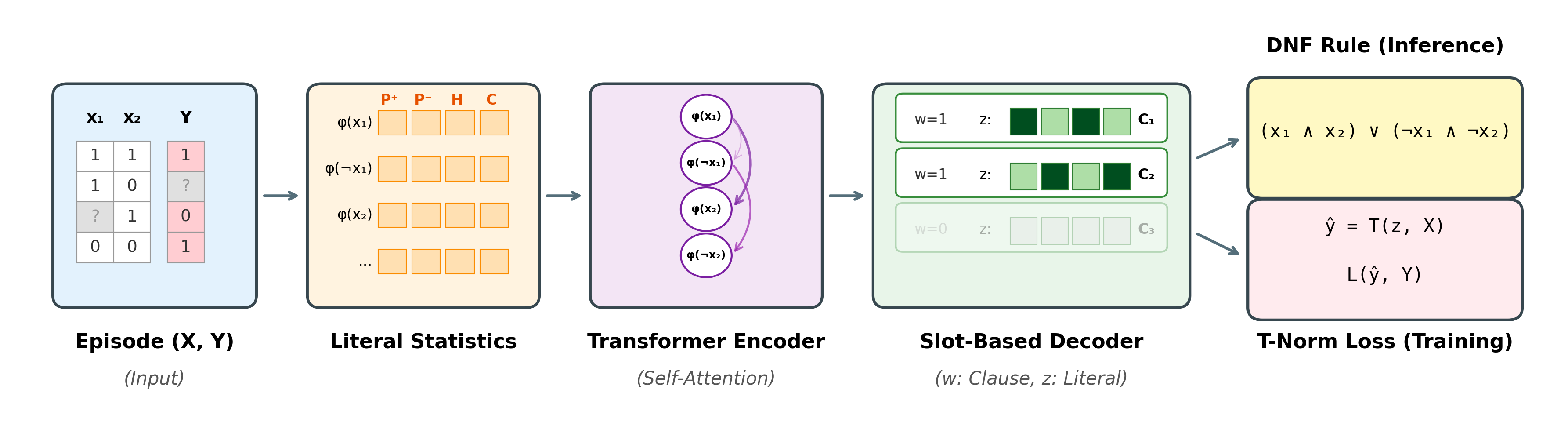
The overall architecture of NRI.
Our paper for Neural Rule Inducer (NRI) has been accepted to IJCAI 2026 and is now available on arXiv. It runs seven pages and tells a clean story: a neuro-symbolic foundation model for zero-shot logical rule induction on tabular data, trained on synthetic Boolean formulas, robust to noise, and able to transfer to UCI benchmarks without retraining.
But seven pages do not leave room for the version of the project where we spent two months staring at a single number while the model was already producing the right answer, where the bug we hunted for six weeks turned out to be the model doing exactly what we had asked it to do, and where we eventually had to admit we were claiming the wrong thing about our own work.
This post is our recount of that journey.
Why we set out to do this
The problem we kept coming back to was something like this. A doctor asks why a model predicted that a patient has diabetes. A loan officer asks why an application was flagged as fraud. A regulator asks why a sentencing recommendation is what it is. None of these people will accept "the model said so" as an answer. Existing explainable-AI tools like SHAP, LIME, or attention maps give them probability heatmaps and feature importances, not the kind of audit they want. They want a rule, written in language they can read, that they can argue with or adopt as policy.
For decades, the answer to that need has been the rule learners: decision trees, RIPPER, classical Inductive Logic Programming (ILP) systems, more recent differentiable ILP variants, and adjacent interpretable tabular methods like RuleFit, skope-rules, and Explainable Boosting Machines (EBMs). They all produce interpretable models, but they share the same fundamental limitation: they are transductive. Every new dataset is a fresh model, retrained from scratch on that dataset's variables. A rule learner trained on patient records does not transfer to fraud detection. There is no equivalent of GPT or CLIP for symbolic rules.
Starting over each time is expensive. In the domains where interpretable rules matter most, labelled data is scarce, hand-curated, and often subject to privacy or consent constraints. A rule learner trained on a small dataset will overfit it: a decision tree with twenty leaves and two hundred cases tells you about those two hundred cases, not about the disease. Each new domain has to choose between gathering more data, which is often impossible, and accepting the overfitting, which is often unacceptable.
We thought a foundation model could break that cycle. A transformer trained on enough text learns what language is, not just what English is. A model trained on enough rule-induction problems should similarly learn what rule induction is, not just any one dataset's rules. This is the same bet TabPFN made for tabular classification, pretraining a transformer on synthetic problems and letting it generalize to new datasets in-context. The output is the only difference: where TabPFN returns a probability, NRI would return a candidate logical rule in a single forward pass, with no retraining and no feature engineering. The few examples in front of it would only need to specify which induction strategy applies, not teach the model how induction works.
If it worked, the use cases were obvious. A clinical informaticist building risk-stratification rules from a small registry would get a candidate rule in seconds, not a SHAP plot to defend in front of a review board. A risk team in fintech or insurance would skip the hand-engineered policy rules and the per-product retraining cycle. A computational biologist hunting for biomarker or activity-cliff rules would have a model that has already seen millions of synthetic rule-induction problems and can transfer across new diseases. A regulator auditing a black-box model would have a tool that returns a small set of human-readable rules instead of probability heatmaps.
That was the bet. Train on enough synthetic rule-induction problems that the model learns the procedure of induction. Evaluate on real problems. See whether anything transfers.
The plan that didn't survive contact with reality
Our first plan was to build on ∂LFIT2, an existing neural rule learner that uses a Set Transformer to encode state transitions and outputs logical rules that explain them. ∂LFIT2 had been shown to work on Boolean network learning, and we wanted to adapt its architectural backbone to our zero-shot foundation-model setting: tabular examples instead of state transitions, classification rules instead of dynamics rules. We also wanted to lift one of ∂LFIT2's main constraints. It required every variable in an observed state to have a known truth value, so it could extrapolate over missing transitions but not over missing entries within a transition. Real tabular data is rarely that clean, and we wanted NRI to handle partial observation within an example, not just at the example level.
We would feed each candidate literal into a Set Transformer to produce a permutation-invariant embedding. A sequential clause composer would assemble clauses one at a time, with each new clause conditioning on the literals earlier clauses had chosen. Gumbel-Softmax with temperature annealing would handle discrete relaxation. Łukasiewicz t-norms would make the whole pipeline differentiable end-to-end. A parsimony loss would keep the rules short and human-readable. We cited multiple papers for inspiration, drew a clean diagram, and felt good about ourselves.
Almost none of that survived.
The first piece to break was the encoder. We were applying a Set Transformer to each literal independently, pooling its truth values across all training examples into a single embedding. That is a beautiful operation that turns out to be exactly the wrong inductive bias for this problem. If two literals are perfectly correlated in your data, you need a representation that knows it. An aggregator that processes each literal in isolation cannot tell you the difference between a useful feature and a redundant one. We discovered this the slow way: we kept watching the model fail to find conjunctions of correlated literals on synthetic data we already knew the answer to, and for a long time we kept blaming the optimizer instead of the architecture.
The fix took three iterations. We first added message passing between literals so the encoder could share information across them. It helped a little. We then added explicit pair-interaction features so the encoder could see how literal pairs co-occurred. It helped some more. Eventually we gave up on learnt aggregation entirely and replaced it with eighteen hand-computed statistics: class-conditional truth rates, entropy, observation rates, mean co-occurrence with other literals, polarity, and various combinations of those. The literal embedding became a simple MLP over those statistics. The shift also resolved the partial-observation goal we had carried over from the start: missing values just become a lower observation rate, no special-casing needed. Looking back, that goal had probably been pulling us toward statistical encoding all along.
That is the encoder you see in the paper. It bears no resemblance to the Set Transformer we started from.
The plateau
Once the encoder worked, we hit a new problem.
Our decoder kept producing clauses that were close to right but never exactly right. To measure how close, we added a clause-level F1 score to the eval harness, which compares the predicted DNF formula against the ground-truth DNF clause-by-clause. The metric climbed to 0.10 and stopped.
For the next two months, that number refused to move.
We attacked it from every angle we could think of. We swept different combinations of supervision and clause-balance weights, expecting one combination to break the plateau. Best F1 of 0.141. We expanded the sweep with different schedules for when each loss kicks in, in case our timing was off. Best F1 of 0.140. We added a pairwise margin supervision that explicitly penalized ground-truth literals scoring below distractors, on the theory that the model was selecting the wrong literals at the margin. F1 of 0.111.
We found and fixed a real bug in the negation indexing during loss computation, where the loss had been silently masking out half the negative-literal supervision signal. We were certain this was the unlock. F1 climbed to 0.149. Recall stayed at 0.10.
We tried coupling the supervision with a counterfactual hinge, which would flip selected literals at training time and ask the model to notice. Clause usage collapsed: the model learned to use only one or two of its eight clause slots, and F1 fell to 0.122. We tried staging it carefully, with a five-thousand-step warmup before the counterfactual weight ramped up, so that the model could find decent clauses before being pressured on necessity. F1 of 0.151. Recall of 0.098.
We switched the decoder mechanism entirely, from a slot-based attention head to a pointer mechanism that emits literals autoregressively until it produces a stop token. F1 of 0.148. Recall of 0.095.
We added a parallel head that forced the same rule to be representable as a conjunction of disjunctions, on the theory that this would create explicit gradient pressure for inhibitory literals. We had high hopes for this one. F1 of 0.105.
Across every single one of these experiments, recall on negated literals sat at exactly zero. The model was not emitting ¬x at all, in any clause, regardless of the loss configuration. We had eighteen statistical features per literal, including explicit polarity, and somehow the gradient signal that should have told the model to use a negative literal was never making it through to the gates.
Some weeks we genuinely thought we were close. Other weeks we ran experiments we knew were unlikely to help, simply because we had no better ideas and the cluster was idle. What we did not yet know was that the answer had been in the model the whole time.
The bottleneck was downstream
The breakthrough, when it finally came, was almost entirely outside the model.
Late one night, we dumped the soft clause-recall metric for one of the stuck checkpoints. This is the metric that the model is actually optimizing during training, before any discretization. We had been ignoring it because it does not correspond to anything you can show in a paper. It reported 0.34. The exported rule was reporting 0.009. Same checkpoint, same weights, same data. The information was already there inside the model. The discretization step was throwing all of it away.
We had written a straightforward greedy export: rank clauses by their gate values, keep the top ones above a threshold, then within each surviving clause rank literals by gate value, keep the ones above a literal-level threshold, output a discrete DNF formula. This sounds reasonable. The problem was a subtle bias in the threshold logic. A literal needed to clear an absolute floor before it could be considered, regardless of its rank within its clause. Negative literals systematically scored lower in absolute terms than their positive counterparts, even when they were the necessary ones to keep. The absolute floor was filtering them out.
So we rewrote the export from the ground up. Instead of forcing every literal to clear an absolute confidence floor before it could be considered, we let the within-clause ranking lead. Each clause kept its highest-ranked literals first, regardless of their absolute scores, and we only fell back to a soft floor when the top-ranked literal in a clause still looked too uncertain to keep. We did not retrain, change the architecture, or add a single parameter. We just swapped out the procedure that turned soft gates into discrete literals.
The same checkpoint that had been exporting 0.009 recall now exported 0.351. Negated literals, which had been entirely absent from every export we had run, suddenly showed up in 65% of active clauses. Clause F1 jumped from 0.091 to 0.516. The model had been doing the right thing the entire time, and we had been throwing away most of what it produced.
Two months of training experiments, fixed by an export bug.
The lesson we took from this was uncomfortable, and it has stayed with us. We had been treating the discretization step as a postprocessing afterthought, the part of the pipeline that you write quickly and never revisit. It was actually doing half the work. Our paper now has a single sentence about clause selection at inference, but that sentence took longer to get right than most of the architecture above it. The gap between our soft training metric and our exported metric was the size of the bug we were missing.
Five things we tried that didn't work
While the recall plateau was happening, we were also running parallel experiments on architectural ideas that seemed obviously correct. They were not.
Per-clause LoRA adapters. Our hypothesis went like this. Every clause shares the same logit projection, so when one clause learns to fire on pattern A, the gradient propagates equally to all the other clauses, which means they all become slightly better at firing on pattern A too. The clauses can never specialize because the geometry of the loss surface forbids it. We tried breaking this symmetry by giving each clause its own per-clause LoRA adapter on the projection layer, with its own low-rank decomposition. We implemented it carefully, using small ranks at first to avoid adding too many parameters. We ran it three times with different rank values and seeds. Performance regressed every time, with our 72.2% baseline falling to 67.5% with adapters. The optimization became visibly unstable, with loss spikes that did not exist in the baseline. After the third regression, we had to accept that LoRA was not just unhelpful here but actively incompatible with the BCE-plus-margin training dynamics. We are still not entirely sure why. Abandoned.
Hierarchical predicate invention. Boolean primitives are limited. XOR and parity functions need exponentially many DNF clauses to express, and many real-world tabular problems have similar structure. We tried letting the model invent its own predicates: take pairs of input literals, compute their conjunctions, and offer those as new candidate literals. The model could then build rules over the enriched vocabulary and capture higher-order interactions in shorter rules. We spent two weeks on the implementation. The fundamental issue turned out to be identifiability. Synthetic training data, which we generate by sampling random DNFs over the input variables, never contains a ground-truth signal that says "this invented conjunction is the right one to keep and that one is noise." The model has no gradient pressure to invent useful predicates rather than pointless ones. We tried adding anti-collapse regularizers that pushed inventions away from each other, two-stage selection mechanisms that filtered candidate predicates before scoring them, and a curriculum that started with simple rules. None of them produced the clean signal we needed. The fix would have required a fundamental redesign of the synthetic data, not hyperparameter tuning, so we abandoned the direction.
Post-hoc teacher-fidelity rule search. A different angle on the recall problem. At evaluation time, we ran the trained model on all training examples to get its predictions, then used those predictions as soft labels for a greedy sequential covering search. Each iteration extracted one clause that covered as many teacher-positive examples as possible, removed those examples from consideration, and searched for the next. This should have produced a rule that matched the model's behavior more faithfully than the model's own discretized output, since the search was explicitly optimizing fidelity. It did not. We wrote three implementations with different greedy strategies, each tested against multiple checkpoints. The greedy search consistently found rules with similar precision and recall to the standard export, never measurably better. The model's discretization was already extracting whatever fidelity was extractable. Abandoned as an evaluation artifact.
Counterfactual necessity training. Standard BCE loss has a known weakness. A literal that happens to be in the rule but is not actually necessary will not get penalized, because flipping that literal does not change the prediction enough to register on a standard cross-entropy loss surface. We added a counterfactual loss that explicitly flipped selected literals during training and penalized the model if the prediction stayed the same. The intuition was clean: this would force the model to only select genuinely necessary literals, which would in turn give us cleaner rules. On synthetic data the loss worked beautifully, with the model converging to compact rules with high precision. On UCI it caused a 7-point regression in accuracy. The signal was too aggressive when the data was noisy. A literal that is necessary on average can be flipped on individual examples without changing the prediction, particularly when the labels themselves are noisy, and the loss interpreted that as "this literal is not necessary, drop it." We kept a much weaker version of this loss in the final model, which provides necessity pressure without breaking on noisy data. The strong version we abandoned.
Balanced Hard-EM with Sinkhorn matching. A direct attack on clause collapse. We assigned each training example to exactly one clause via a hard EM step, then balanced the assignments across clauses with a Sinkhorn projection so that no single clause could dominate. This forced every clause to own a portion of the data and took away the optimizer's freedom to collapse onto a few high-scoring clauses. The math was clean. The implementation passed unit tests. Synthetic experiments showed the matching working as designed. It made no measurable difference to clause F1 or to UCI accuracy. We diagnosed that the gradient consensus problem operates at a level the matching layer cannot reach: even when clauses are forced to own different examples, the shared logit projection still pushes their parameter updates into agreement, and the matching just shuffles the example assignments without changing what the clauses actually represent. Abandoned.
The pattern across all five was the same: a hypothesis that addresses what looks like the bottleneck, an implementation that takes one to three weeks, a result that either regresses or matches baseline, and a long internal debate before we finally call it. Looking back, three of those five were attempts to fix behavior we would later recognize as the model doing exactly what we had asked of it. We did not see it at the time.
The bug was a feature
Through every one of the failed approaches above, one symptom kept showing up. Our model would converge on using two or three of its eight clause slots and leave the rest at near-zero gate values, regardless of what we did to encourage diversity. We saw the same pattern with LoRA. With FiLM modulation. With explicit diversity penalties on the clause embeddings. With sequential training. With Hard-EM and Sinkhorn matching. Whatever architectural variation we tried, the few-clauses-active behavior was the one constant we could not eliminate.
We called the phenomenon clause collapse. We treated it as a failure mode. Every fix we tried for it either failed outright or regressed something else, and after about six weeks of fighting it head-on, we stopped. Then we did something we should have done at the start: we ran an experiment to measure whether collapse was actually helping or hurting.
The setup was simple. Across our UCI evaluation runs, we separated the seeds where the model collapsed, meaning multiple clause slots producing identical or near-identical literals, from the seeds where it produced distinct clauses, and compared the accuracy of each group. We expected the distinct runs to come out ahead, vindicating six weeks of debugging. They did not. 71.2% of runs collapsed. The collapsed runs averaged 69.3% accuracy. The distinct runs averaged 62.3%. The model was doing systematically better when it collapsed than when it did the thing we had been trying to force it to do.
The per-dataset breakdown was sharper still. On Adult, the income-prediction benchmark from US Census data, collapse improved accuracy by 15.7 points. On Spambase, by 10.9 points. On Tic-Tac-Toe, by 8.2 points. On Kr-vs-Kp, the chess endgame benchmark, by 7.4 points. The only dataset where collapse meaningfully hurt was mushroom, where distinct clauses outperformed by 14.8 points. Mushroom has multiple genuinely informative features (odor, spore color, stalk shape, gill spacing), and the model is leaving accuracy on the table by failing to use them. Everywhere else, collapse was the better strategy.
What stood out from the verification was not just that collapse helped, but why. When the model produced distinct clauses, those clauses were often wrong individually, or they contradicted each other on overlapping examples, or they covered the same positives in inconsistent ways. The collapsed model was not failing to use its capacity. It was playing safe. The model had found one rule that worked across the training distribution and was holding onto it rather than reaching for additional ones that were more likely to be incorrect.
The theoretical reason for this fell out of how we had set up training. We augment every training episode with distractor features that correlate with the label in one half of the examples and anti-correlate in the other half. The objective rewards features whose predictive power survives that switch. We call this setup spurious environment regularization, and most features do not survive it. The supply of robust, environment-invariant features in any given episode is small, often just one or two atoms. A clause that contains spurious literals fails in one of the two environments. A clause that contains only causal literals succeeds in both. The pressure on the model to find invariant clauses is enormous, the supply of robust patterns is limited, and the loss function is asking the model to be picky.
This is in the same family as invariant risk minimization (IRM) and domain-generalization training. Where IRM uses environments to find features that generalize across distributions, we use synthetic environments to find clauses that generalize across episodes.
Of course only two or three clauses end up active. The model is correctly recognizing that there are only two or three patterns worth committing to in any given episode, and using a slot for a less-confident pattern would risk a clause that fails the environment switch and tanks the entire rule.
This was the first time we resolved a problem by changing what we believed about the goal, not by adding code. Once we accepted clause collapse as a feature, several decisions followed naturally. We dropped the diversity-enforcing experiments. We promoted a new reference checkpoint trained with stronger spurious-environment regularization. We started measuring, on every new dataset, whether the few-clause behavior was actually worse than the alternative, instead of assuming it was.
The reframe
By mid-January we had a clear picture of where NRI stood against the baselines, and it was less competitive than we had hoped.
We ran a comprehensive few-shot study against RandomForest across all UCI datasets, with sample sizes ranging from 1 to 50 per class. At 1 sample per class, NRI hit 43.8% and RF hit 43.7%. A statistical tie. At 2 samples, the gap opened to 7.9 points. At 5 samples, it widened to 14.3 points, the worst point in the entire study. By 50 samples and beyond, the gap stabilized at 9.6 points, with NRI consistently a step behind. We were being beaten by a thirty-year-old algorithm by ten percent across most of our operating range.
Publishability was never the question. A zero-shot foundation model for symbolic rule induction is novel enough that the paper was going to land somewhere on the strength of the contribution alone. There was no prior work to compare directly against, and the architectural claim held regardless of UCI numbers. What we had wanted was for SOTA-competitive accuracy to be a bonus on top of the novelty: "and by the way, NRI is also competitive with the strongest tabular ML methods you would reach for." That part was not going to happen.
So the question was which of our actual strengths to lead with. We had three options: keep grinding on UCI in the hope that some architectural change would close the gap, frame the paper around competitive-on-a-subset numbers, or lead with the two things NRI was genuinely best-in-class at and present the SOTA gap as the cost of the interpretability we were buying.
We picked the third. NRI would be presented as a zero-shot hypothesis generator, with the 10-point accuracy gap framed honestly as the price of interpretability, the cost of insisting that every prediction comes with a human-readable rule attached.
In our case, two things were genuinely best-in-class once we stopped trying to make accuracy the headline.
The robustness curves are not even close. NRI loses to RIPPER and decision trees by 6 points at 0% label noise and beats them by 17 points at 30% noise. Symbolic methods overfit because they fit training data exactly, while NRI cannot, because its inputs are sample statistics that smooth over individual examples. We did not design this in. It fell out of the architecture, and once we started to look at it as a feature instead of a side-effect, it became one of the central claims of the paper.
Zero-shot transfer was the other one. No other rule learner in the literature transfers without retraining, full stop. NRI's lower per-dataset accuracy is the price of generality, and we now have an explicit measurement of that price.
We rewrote the paper around those two claims in about three days. It is a smaller paper than the original draft, which we had been working on for two months, but it is a more honest one. The reviewers ended up caring more about the robustness and zero-shot story than they did about UCI absolute numbers. We probably should have figured that out earlier.
What surprised us
A few empirical findings made us rethink the model.
The clinical plausibility of the rules was the biggest one. On Pima diabetes, NRI's rule fires when plasma glucose, blood pressure, skin thickness, and age are all above their respective medians. On Wisconsin breast cancer the rule requires elevated clump thickness, cell size, cell shape, and bare nuclei. On spambase, NRI picks up the absence of HP-internal vocabulary words like "george" or "meeting" as a spam indicator, which is the well-known dataset artifact (the corpus comes from one HP employee's email) known to dominate that benchmark. We did not curate any of these rules. They are the raw output of running the same checkpoint on different datasets. A clinician would write down something close to the breast cancer rule unprompted. NRI did, in zero shot, on a checkpoint trained only on synthetic Boolean formulas. We still find this surprising.
The two-sample regime was the second surprise. RandomForest, a deeply over-parameterized ensemble that has no business being competitive at two examples per class, holds its own against NRI in that regime. The gap is under 8 points at 2 samples, and only opens up as more data comes in. We eventually concluded that pretraining on synthetic Boolean formulas teaches a useful prior, but per-task fitting overtakes it once enough data exists to fit. This is the opposite of what we had expected. We had assumed pretraining would give NRI a permanent advantage at small sample counts. It does not. Pretraining gives a temporary advantage instead, and the moment the dataset has enough information to specify the right rule, a model that fits that dataset directly will win.
The third surprise was the extent to which the model's failure modes turned out to be reasonable behavior in disguise. Clause collapse was a feature. Negative-literal recall of zero was an export bug. The seed-to-seed variance that looked like training instability turned out to be the optimizer correctly finding different local minima when the synthetic data did not constrain the rule uniquely. Each of these "obvious failures" took weeks to recognize as anything else, and the longer we worked on the project the less confident we became that any given symptom was actually broken.
What we would do differently
Four things, in order of how much pain they would have saved us. Three of them are versions of the same lesson: we should have noticed the model was telling us something earlier.
We should have tested on real data sooner. We spent the first two months evaluating only on synthetic Boolean formulas because we wanted the synthetic-to-real transfer to be a clean, controlled comparison rather than a scramble. The synthetic-to-real gap turned out to be bigger than we anticipated, and most of the architectural decisions we made in those two months had to be revisited once we started running UCI. The set-aware encoder, the Gumbel-Softmax decoder, the Łukasiewicz t-norm, and the original loss configuration all looked acceptable on synthetic and failed on real data for different reasons. If we had been running UCI from week three onward, even at low fidelity, we would have caught these failures much earlier.
We should have treated the export step as a research surface from the start. It is not a postprocessing afterthought, and treating it that way cost us two months on the recall plateau. The right model for a foundation rule inducer is one where the soft and discrete pipelines are designed together, not where the soft pipeline is the science and the discretization is an engineering detail.
We should have stopped fighting clause collapse earlier. Six weeks and several failed approaches went by before we realized the loss function was actively asking for collapse. The signal was already in the metrics for most of those six weeks. We just kept reading it as a bug because we had walked in expecting all eight clause slots to be active, and never updated that expectation when the data told us otherwise.
We should have adopted the characterization framing from the start. Reframing the paper from leading with SOTA to leading with interpretability-cost took three weeks in January. If we had committed to that framing from the beginning, we could have designed the experiment suite around it instead of retrofitting. We added the robustness curves and the zero-shot transfer numbers, which are now the heart of the paper, late in the process, because we had not realized they were the heart until very late.
Where this leaves us
Our paper makes a single coherent claim, and most of those six months was figuring out the cleanest way to argue for it. A foundation model for symbolic rule induction is possible. It transfers zero-shot to new domains, and the price of that generality is a measured accuracy gap that is largest in the high-data regime and smallest in the low-data and high-noise regimes where it matters most.
We believed three or four different things about the project before we landed on this one. Most of that iteration is not in the paper, but it is in this post. Six months of work, hundreds of experiments, fourteen hundred research notes in our project log. The paper presents the destination. This post is the trail behind it.
The lessons stayed with us, but they are specific to how NRI failed for us. We learned that pooling-based encoders destroy cross-predicate correlations only after we spent two months blaming the optimizer. We learned that soft training metrics do not always survive discretization only after we threw away two months of training experiments without checking the export. We learned that clause collapse can be the loss function doing its job only after we spent six weeks trying to fix what was not broken. And we learned that the right answer to a stuck headline is sometimes a different headline, only after we admitted we could not beat random forest.
The thread running through all four is the same one: we kept treating the model's correct behavior as failure, and only learned to recognize the pattern after each instance had cost us weeks of misdirected work. None of these are universal lessons. They are the ones our particular failures forced us to internalize, and we suspect every research project has its own version of this same misreading.
What is next for NRI is more interesting than the lessons. The model we shipped only handles boolean variables and propositional rules, which is a small slice of what interpretable rule induction could be. The natural next direction is continuous attributes through discretization or learned fuzzy predicates, and after that, first-order relational rules with multiple predicates and arguments per clause. We are also curious whether the recipe (pretrain on synthetic problems, encode each input by identity-free statistics, decode in parallel) generalizes beyond rule induction. The same approach might transfer to other interpretable structure learning problems like causal discovery, program synthesis, or decision-list induction. We think this is what a foundation model for neuro-symbolic AI could look like, and we want to see how far the recipe goes. The next six months will tell us a little. The six months after that will tell us more.
Code, paper, and BibTeX are at the project page.
Have comments or want to have discussions about the contents of this post? You can always contact me by email.