A Foundation Model for Zero-Shot Logical Rule Induction
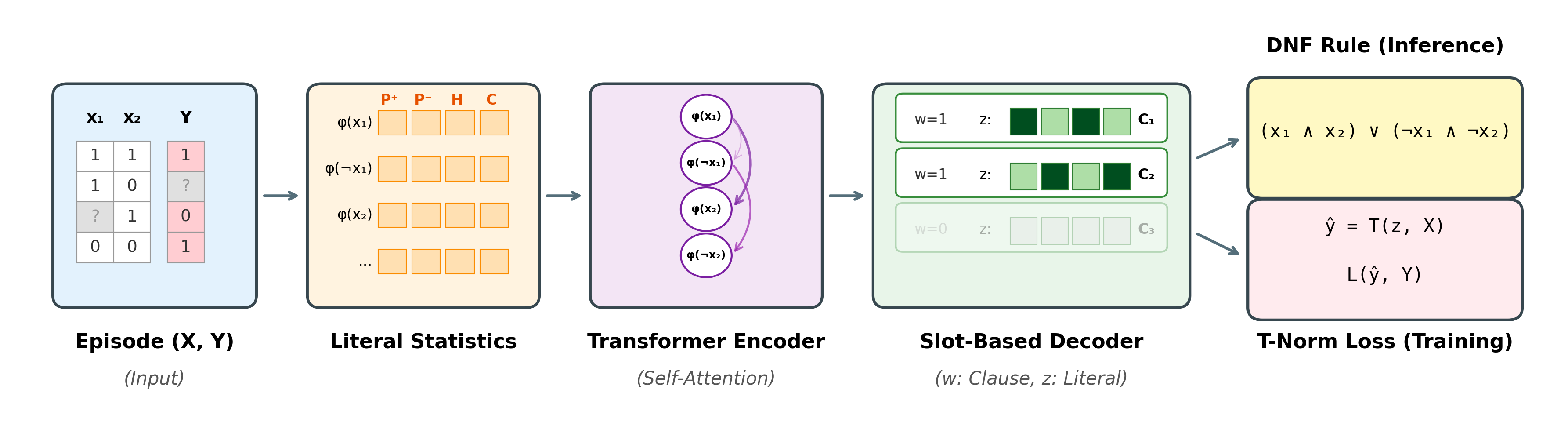
Symbolic rule learners are interpretable, but they have to be retrained from scratch on every new dataset, overfit noisy labels, and transfer nothing from one problem to the next. To break this trade-off, we proposed the Neural Rule Inducer (NRI), a foundation model that performs logical rule induction in a single forward pass (Phua, 35th International Joint Conference on Artificial Intelligence, 2026). Trained once on millions of randomly generated synthetic Boolean formulas, NRI induces interpretable DNF rules zero-shot on new tabular tasks, with no retraining, no fine-tuning, and no per-task weights. The key idea is to never look at variable names: each literal is described by 18 identity-free statistics, and a slot-based decoder synthesizes candidate clauses in parallel, so the model is invariant to both predicate identity and clause order. The entire pipeline from raw episode to predicted label is differentiable, executed under the product T-norm, and discretizes into a symbolic DNF at inference time.
Applied directly to 14 UCI tabular tasks, a single NRI checkpoint produces short, readable rules that align with domain knowledge — including the clinically plausible plasma-glucose-and-age signature on the Pima diabetes dataset, and the canonical odor-based predictor on the mushroom benchmark. NRI also degrades smoothly under label noise where classical rule learners collapse, and stays above 92% accuracy even when 32 spurious distractor features are added at correlation 0.9. More details and code are available on the project page.
Learning Logic Programs from Dynamic Systems
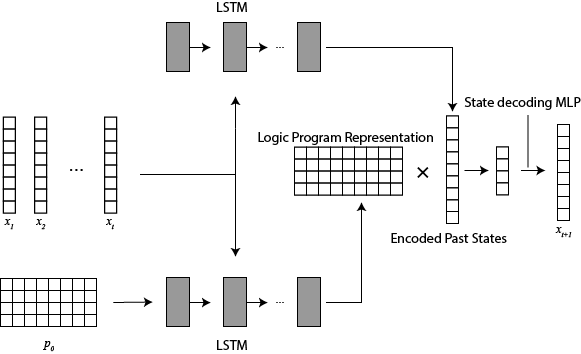

My main research focus has been on a neuro-symbolic method for learning transition rules from time series data. By feeding the time series into an LSTM (Long-Short Term Memory) and using the corresponding logic program as the hidden states, the LSTM learned representations of the logic program and used them to predict the next state — showing that a single neural network can classify time series originating from different dynamic systems and predict the next state from historical data alone (Phua, et al. 27th International Conference on Inductive Logic Programming, 2017). We then showed that a neural network can also identify time series that come from the same dynamic system, and revised our method to take background knowledge into account (Phua, et al. IfCoLog Journal of Applied Logics, 2019). Training the LSTM to identify time series from the same system further improved the accuracy of our method.
Building on these results, and leveraging the strength of neural networks for pattern recognition, we proposed a method that learns logical rules directly from state transition data (Phua, et al. 29th International Conference on Inductive Logic Programming, 2019). By classifying the rules inherent in the transitions, the network outputs a logic program that represents the dynamic system. We added a constraint on the learned rules so the network can classify all possible rules without modifying its architecture, and proved that the resulting method is robust against noise. This work was recognized by the community, and we received the Best Student Paper award. Next, by exploiting invariant properties inherent in logic systems — in particular, invariance to the order of the state transition input — we suppressed the combinatorial explosion that comes from trying to classify all possible rules (Phua, et al. 1st International Joint Conference on Learning & Reasoning, 2021). We proposed a neural network architecture that bakes this invariance in, and by considering multiple logical rules in a single inference, we also reduced the network's memory requirements. This let us apply our method to larger dynamic systems, bringing it a step closer to real world applications.
We have since extended our method to delayed dynamic systems, demonstrated robustness against missing data, and generalized it from the synchronous semantics of all our previous work to asynchronous semantics.
Class-Incremental Learning using Generative Models

Statistical machine learning methods like neural networks are known to suffer from catastrophic forgetting: training a model on a new task tends to erase what it learned on previous ones. The field that studies this phenomenon and its mitigation is called incremental learning. One branch of it considers classification, where at each training step only a limited number of classes are available. Many methods have been proposed with various degrees of success, and the one we consider combines knowledge distillation — training a model to retain knowledge from another model — with replay memory, a fixed-size buffer of examples from previous classes. Previous methods populate this buffer with instances from the training set, but the limited memory budget caps how many instances can be retained, which limits performance. In this work, we proposed replacing the replay memory with widely available generative models, and devised a method for prompting the generative model to obtain relevant images. This improved existing methods by 1~3%, and we also found there is a sweet spot between the final accuracy and the number of images sampled from the generative model.
Results of this work have been published in the workshop paper (Jodelet, et al. 1st Workshop on Visual Continual Learning, 2023), which was chosen for the best paper award.
Consistent Identification of Gene Sets from Cell Sequencing Data
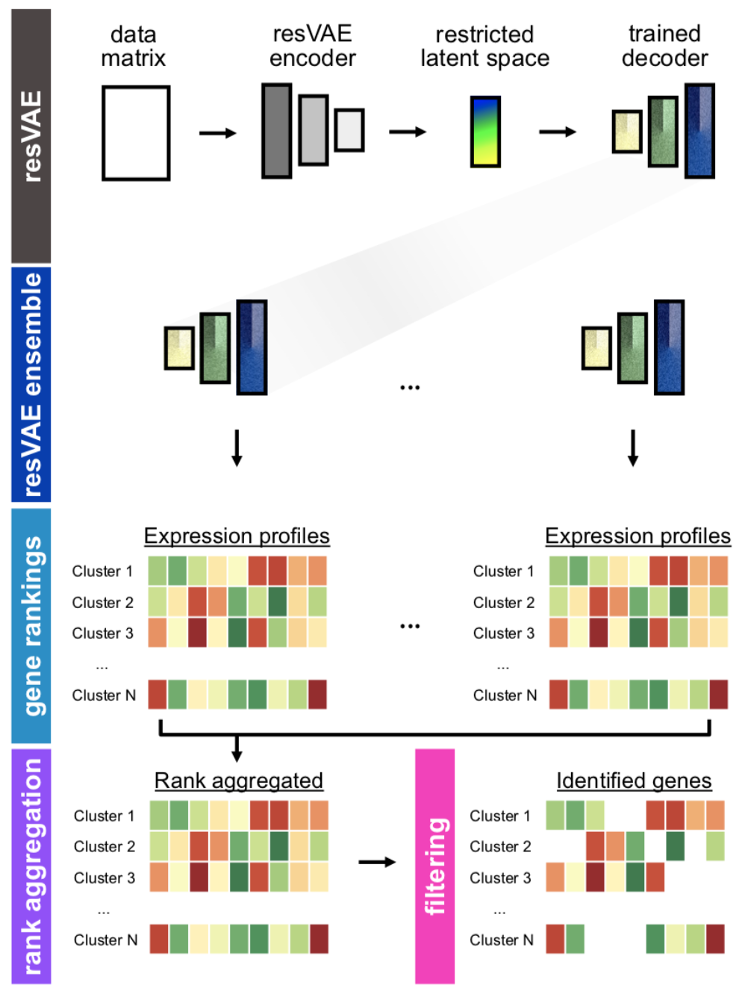
In collaboration with the Berlin Institute of Health, we proposed a method that identifies important gene sets for different cell types from single cell sequencing data. Biologists work under time pressure when analyzing such data, and quickly identifying gene sets can accelerate the development of important drugs. Previous methods focused only on whether gene sets could be extracted at all, but the randomness inherent to statistical machine learning meant that each run could produce a different set of genes, complicating the analysis. By utilizing an ensemble of resVAEs, we were able to stabilize the identified gene sets. We further show that the choice of activation function has large implications for stability, and thus chose one that provides even greater stability.
Results of this work were published in the journal paper (Ten, et al. Frontiers in Cell and Developmental Biology 11, 2023).
Have questions or want to know more about my research work? You can always contact me by email.