ゼロショット論理規則帰納のための基盤モデル
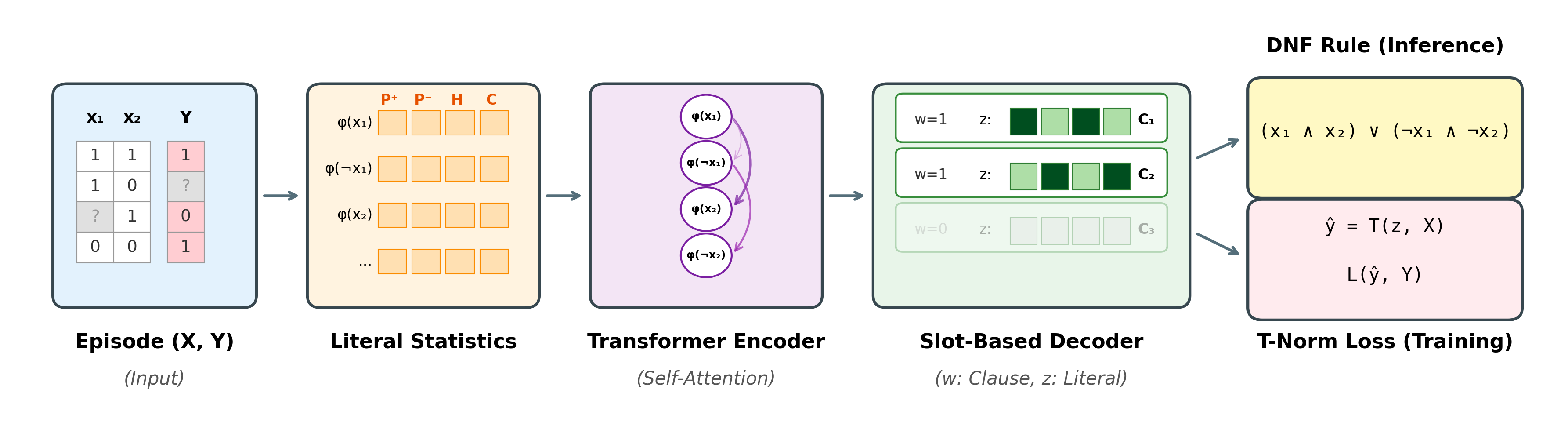
決定木やRIPPER,帰納論理プログラミング (ILP) などの記号的な規則学習手法は,解釈可能性(説明可能AI/XAI)の観点から望ましいものの,新たなデータセットごとに一から再学習する必要があり,ラベルのノイズを過学習しやすく,異なるタスク間で知識が転用されないという課題を抱えている.このトレードオフを解消するため,深層学習と記号推論を融合するニューロシンボリックAIの立場から,単一の順伝播のみで論理規則の帰納を行う基盤モデル Neural Rule Inducer (NRI) を提案した(Phua, 35th International Joint Conference on Artificial Intelligence, 2026).NRIは大量にランダム生成されたブール式で一度だけ事前学習させると,新たな表形式データ(テーブルデータ)タスクに対し再学習やファインチューニングなしに,解釈可能なDNF(選言標準形)規則をゼロショットで帰納できる.鍵となる発想は変数名を一切参照しないことである.各リテラルを18個の同一性に依存しない統計量で表現し,スロット型デコーダで候補節を並列に合成することで,述語の同一性および節の順序の双方に不変なモデルを構成した.生のエピソードから予測ラベルまでの全過程は微分可能であり,積T-ノルムの下で実行され,推論時には記号的なDNFへ離散化される.
UCIの14個の表形式データタスクへ直接適用したところ,単一のチェックポイントでドメイン知識と整合する短く読みやすい規則が得られた.Pima糖尿病データセットでは血漿グルコース値と年齢を組み合わせた臨床的に妥当な規則,マッシュルームベンチマークでは古典的な「臭い」を中心とする予測器など,それぞれの分野で標準的に用いられる特徴量が再現された.また従来の規則学習手法がラベルノイズに対して急激に性能を落とすのに対し,NRIの精度は滑らかに低下する.さらに,相関0.9で32個の擬似変数を加えても92%以上の精度を維持した.詳細とコードはプロジェクトページ(英語)で公開している.
動的システムからの論理プログラムの学習
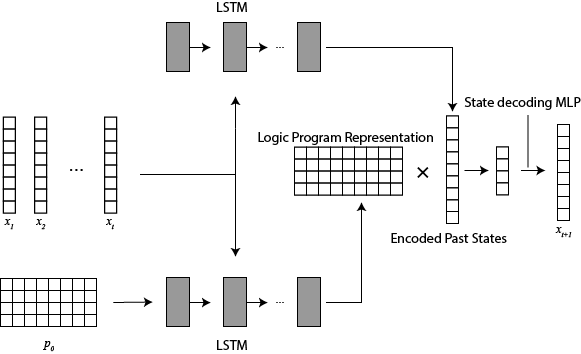

私はこれまで,深層学習と記号的論理機械学習を融合し,時系列データから遷移規則を学習する手法の確立に取り組んできた.LSTM (Long-Short Term Memory) に時系列データを入力し,対応する論理プログラムを隠れ状態として用いることで,LSTMが論理プログラムのベクトル表現を学習し,その表現を用いて次の状態を予測できることを示した(Phua, et al. 27th International Conference on Inductive Logic Programming, 2017).これにより,単一のニューラルネットワークが異なるシステムから得られる時系列データを分類し,かつ過去のデータのみから次の状態を予測できることを確認した.次に,同一システムから得られる異なる時系列データを識別できることも示し,背景知識を取り込んで予測を改善する手法を提案した(Phua, et al. IfCoLog Journal of Applied Logics, 2019).LSTMが学習した行列表現を分析することで,同一システムから得た表現が互いに近接することを示し,これらを繰り返し入力して学習させることで予測精度がさらに向上することも確認した.
これらの結果と,ニューラルネットワークのパターン認識能力を活かして,状態遷移データから直接論理規則を学習する手法を提案した(Phua, et al. 29th International Conference on Inductive Logic Programming, 2019).時系列データに内在する規則を分類することで,対象とする動的システムを表す論理プログラムを出力する.学習対象の論理規則に制約を設けることで,ニューラルネットワークの構造を変更せずにあらゆる規則を列挙して分類できるようにし,かつノイズに対する頑健性も証明した.この成果が評価され,最優秀学生論文賞を受賞した.次に,記号論理に内在する不変性を利用して,あらゆる論理規則を分類しようとした際に生じる組合せ爆発を抑制した(Phua, et al. 1st International Joint Conference on Learning & Reasoning, 2021).特に入力される状態遷移の順序に対する不変性に注目し,これを組み込んだネットワーク構造を提案した.さらに,一度の推論で複数の論理規則を扱えるようにすることで,ニューラルネットワークのメモリ消費量も削減した.これによりより大規模なシステムにも適用可能となり,実世界応用に一歩近づいた.また,記号論理で学習した結果をより理解しやすくする研究を,2021年度の特別研究員奨励費により推進した.
その後,本手法を遅延のあるシステムへ拡張し,さらに学習データに欠落がある場合の性能を従来手法と比較して,実世界データでより頑健であることを確認した.加えて,これまで同期システムの遷移にのみ対応していたモデルを,非同期システムの遷移にも対応するよう一般化した.
生成モデルによるクラス増分学習

ニューラルネットワークなどの統計的機械学習手法には,破滅的忘却と呼ばれる問題がある.すでに学習済みのモデルに新しいタスクを学習させると,それ以前のタスクに関する知識を失ってしまう現象である.この現象を研究し,緩和を試みる分野を継続学習と呼ぶ.その中でも,各ステップで学習対象となるクラスが限定されるクラス分類タスクをクラス増分学習という.これに対しては多くの手法が提案されており,本研究では蒸留とリプレイメモリを組み合わせた手法に注目する.蒸留は学習済みモデルの知識を別のモデルに移転する手法であり,リプレイメモリは過去のクラスのデータを一定量保持しておくバッファである.従来手法では学習データ中のサンプルをそのままバッファに保持していたが,メモリには限りがあるため保持できる数も限られ,性能を頭打ちにしていた.本研究では,このリプレイメモリを広く利用可能な生成モデルに置き換える手法を提案し,関連する画像を生成モデルから得るためのプロンプト手法も考案した.これにより既存手法の精度を1~3%向上させ,また生成モデルから得る画像枚数と最終精度の間に最適なバランスが存在することも明らかにした.
本研究の成果は,国際学会にて発表し(Jodelet, et al. 1st Workshop on Visual Continual Learning, 2023),最優秀論文賞を受賞した.
細胞配列データから安定的に重要な遺伝子を識別する
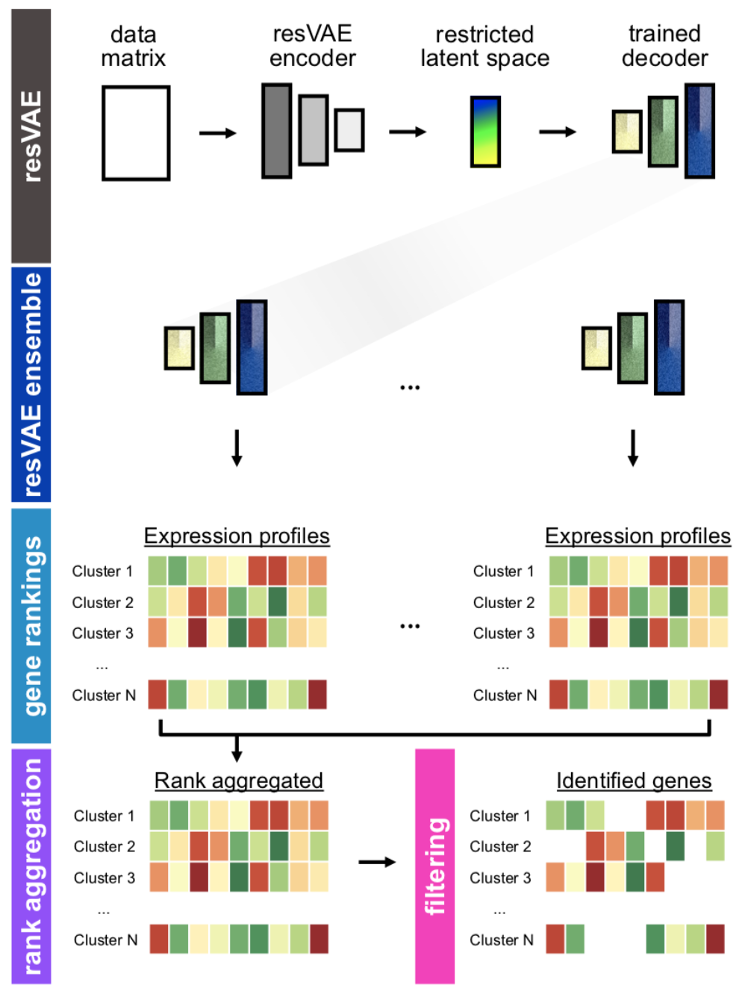
ベルリン健康研究所との共同研究において,シングルセルシーケンシングデータから細胞種ごとに重要な遺伝子セットを識別する手法を提案した(Ten, et al. Frontiers in Cell and Developmental Biology 11, 2023).生物学者はこのようなデータを限られた時間で解析する必要があり,重要な遺伝子セットを迅速に同定できれば,創薬の効率化につながる.従来手法は遺伝子セットを抽出できるか否かにのみ焦点を当てていたが,統計的機械学習に内在するランダム性のため,実行のたびに異なる遺伝子セットが得られ,後段の解析を複雑にしていた.本研究ではresVAEのアンサンブルを用いることで,識別される遺伝子セットを安定化させた.さらに,活性化関数の選択が安定性に大きく影響することを明らかにし,より高い安定性を与える活性化関数を選択した.
質問がある場合,あるいは私の研究についてもっと知りたい場合は,メールで連絡ください.