A TabPFN for Rules: Zero-Shot Rule Induction with NRI
Published on July 3, 2026
TabPFN showed that a transformer pretrained purely on synthetic data can classify real tabular datasets it has never seen. NRI makes the same bet with one change: instead of a probability, it hands you the rule.
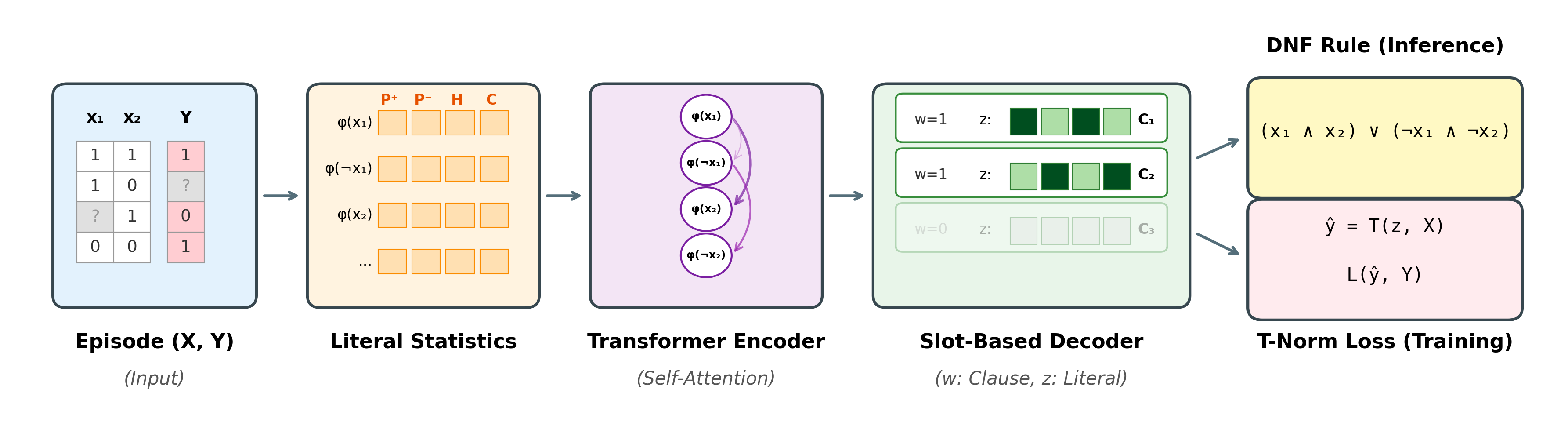
The NRI pipeline: from tabular examples to a discrete DNF rule in a single forward pass.
If you work with tabular data, you have probably come across TabPFN: a transformer pretrained on millions of synthetic classification problems that predicts on new datasets in-context, in a single forward pass, with no per-dataset training. Since its second version was published in Nature, "tabular foundation model" has gone from curiosity to category. The bet behind it is simple to state. A model trained on enough classification problems learns what classification is, not just what any one dataset looks like.
Our IJCAI 2026 paper takes the same bet and changes the output. The Neural Rule Inducer (NRI) is a foundation model for logical rule induction. Its only training data is millions of random synthetic Boolean formulas, and it is then applied zero-shot to tabular datasets it has never seen: no retraining, no fine-tuning, no per-task weights. TabPFN answers with a probability. NRI answers with a candidate rule in disjunctive normal form (DNF), short enough to read, produced in one forward pass.
That difference matters in exactly the places tabular ML gets used under scrutiny. The people who have to act on a prediction in medicine, lending, or a regulatory audit rarely need another feature-importance plot. They need a hypothesis they can check: a short rule that a domain expert can read, argue with, and accept or reject on its merits.
What you actually get
Here is the rule the pretrained checkpoint produces on the Pima diabetes dataset, zero-shot:
plas >med ∧ pres >med ∧ skin >med ∧ age >med
Read it as: plasma glucose, blood pressure, skin thickness, and age all above their medians. That is a clinically plausible summary, and at 68.0% five-fold CV accuracy it beats EBM (66.9%) and RIPPER (66.8%) trained per-task on this dataset. On Wisconsin breast cancer it selects thicker clumps, irregular cell size and shape, and prominent bare nuclei, which is close to what a pathologist would write down unprompted. Neither example is curated. Both come straight from the one pretrained checkpoint, applied to datasets it had never seen.
How it works, briefly
The key design decision is that NRI never looks at variable names. Each candidate literal is described only by 18 identity-free statistics: class-conditional truth rates, entropy, observation rates, co-occurrence with other literals, and polarity. A slot-based decoder then assembles candidate clauses in parallel. The model is therefore invariant to both predicate identity and clause order, so a rule-induction problem about genes looks the same to it as one about loan applications. That invariance is what lets a single checkpoint, trained only on synthetic formulas with 6 to 12 variables, transfer to 14 UCI tasks of which 12 have more features than anything it saw in training. Everything stays differentiable during training, using soft logic under the product T-norm, and at inference the soft gates are snapped into a discrete symbolic rule, in about 12 ms for 512 variables.
What it costs, honestly
Zero-shot interpretability is not free, and we would rather state the price than have you discover it. Averaged over the 14 UCI tasks, NRI reaches 69.7% accuracy, about 13 points behind EBM trained per dataset and roughly 10 points behind random forest across most of the operating range. If your only goal is squeezing accuracy out of a large, clean dataset, train XGBoost on it. That is the right tool. The gap is what you pay for getting a short, readable rule out of a model that has never trained on your data, and we measured it so you don't have to guess.
Where it wins
Three places, all of which matter most in the settings where interpretable rules are wanted in the first place.
Label noise. Classical rule learners chase an exact fit of the training data, and the bill arrives as soon as some labels are wrong. At 0% noise, RIPPER and decision trees beat NRI by about 6 points. By 30% label noise the ranking has inverted and NRI leads by 17, with the crossover happening around 15% noise. NRI is structurally unable to memorize single rows: it only ever sees aggregate statistics, and aggregation smooths the noise away.
Spurious features. We append distractor features that correlate with the label but have no causal relationship to it. NRI stays above 92% accuracy across the whole grid, including 32 distractors at correlation strength 0.9, because the training regime explicitly rewards clauses whose predictive power survives an environment switch.
Zero-shot transfer itself. We know of no other rule learner that can be handed a new domain without any retraining. Every decision tree, every RIPPER model, every ILP program is fit from scratch per dataset. NRI's per-dataset accuracy is the price of being the exception.
When to reach for it
NRI is best used as a zero-shot hypothesis generator. If you have a small registry of patient records and need a candidate risk-stratification rule you can defend in front of a review board; if you are auditing a black-box model and want a human-readable summary of what drives a label; if your data is noisy, scarce, or expensive to label: that is the regime NRI was built for, and the regime where its robustness advantages are largest. It is not a leaderboard model, and it does not want to be.
Limitations and what's next
The shipped model handles Boolean variables and propositional rules, and continuous features are binarized at their medians. Exact recovery of the ground-truth rule also degrades as rules get more complex, from 99.5% for single-literal rules down to 24% in the hardest regime we measured, though prediction accuracy stays high because the recovered rules are usually semantically close. The natural next steps are learned predicates for continuous attributes, and after that, first-order relational rules. We are also curious whether the same recipe of synthetic pretraining, identity-free statistical encoding, and parallel decoding can be pushed to other interpretable structure learning problems.
The paper, code, and BibTeX are on the project page, and the preprint is on arXiv. If you want the unvarnished six-month story behind the model, including the two months we spent fixing what wasn't broken, that is in the NRI research diary.
Have comments or want to have discussions about the contents of this post? You can always contact me by email.